RoboPanoptes:
The All-Seeing Robot with Whole-body Dexterity
Xiaomeng Xu1 Dominik Bauer2
Shuran Song1,2
1Stanford University 2Columbia University
RoboPanoptes is a robot system that utilizes all of its body parts to sense and interact with the environment, enabling novel manipulation capabilities such as sweeping multiple or oversized objects, unboxing in narrow spaces, and precise multi-step stowing in cluttered environments.
1x
1x
1x
1x
Technical Summary Video
System Overview
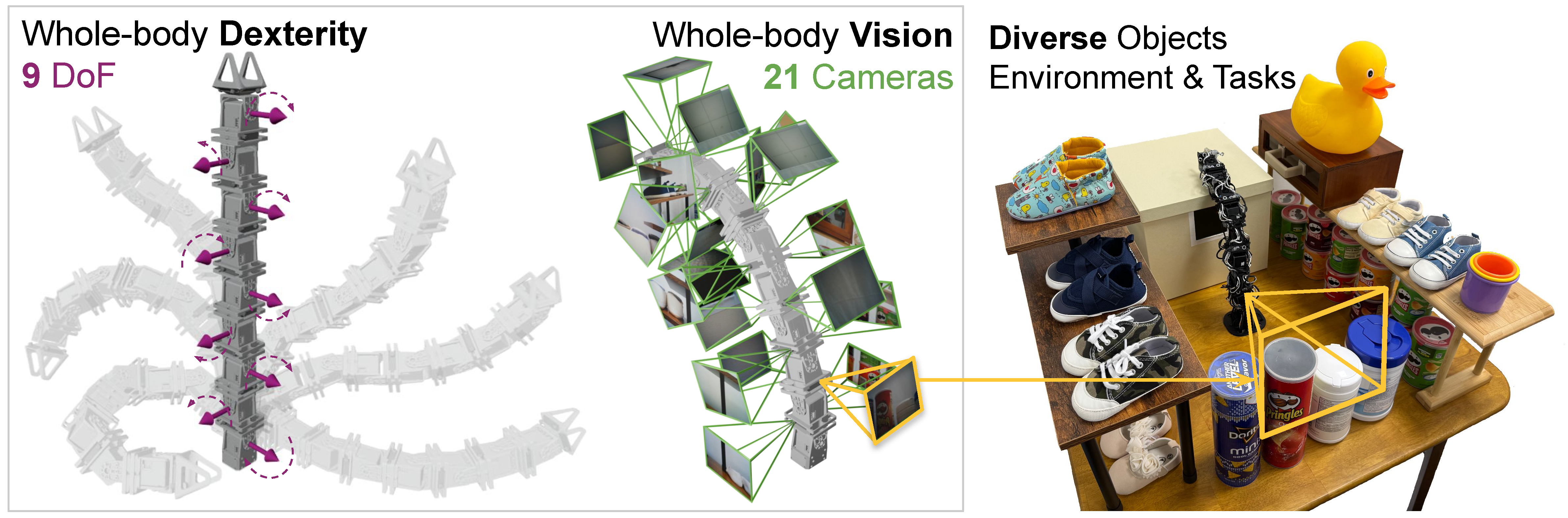
RoboPanoptes achieves whole-body dexterity through whole-body vision.
Its whole-body dexterity allows the robot to utilize its entire body surface for manipulation, such as leveraging multiple contact points or navigating constrained spaces.
Meanwhile, whole-body vision uses a camera system distributed over the robot's surface to provide comprehensive, multi-view observations of its environment and visual feedback of its own state.
At its core, RoboPanoptes uses a whole-body visuomotor policy that learns complex manipulation skills directly from human demonstrations, efficiently aggregating information from the camera system while maintaining resilience to sensor failures.
Experiments
(1) Unboxing 📦
Task The robot is tasked with opening a box with a lid: locate the small side hole of the box, enter the box through the hole, drag the box closer, extend its body inside the box, lift the lid, and slide the lid aside to fully open the box.Comparisons [Top-down Camera] policy struggles to determine the correct reaching height. [Head Camera] policy moves in the wrong direction. [w/o Camera Pose Encoding] policy struggles to open the lid, and at locating and entering the hole. [w/o Blink Training] policy underperforms in scenarios with camera dropout.
1x
1x
1x
1x
1x
1x
1x
1x
(2) Sweeping 🧱
Task The robot is tasked to sweep all objects (small or large, randomly placed on a table or under the shelf) into a target region around its base.Comparisons [Top-down Camera] policy fails to detect objects under the shelf and often knocks down tall objects. [Neck Cameras] policy struggles with objects located behind the robot due to self-occlusion.
1x
1x
1x
1x
1x
1x
1x
1x
1x
(3) Stowing 👟
Task The robot performs a sequence of actions to stow shoes in a drawer: hook and pull the drawer handle to open it, pick up a pair of shoes (one by one), place the shoes inside the drawer, and push the drawer to close it.Comparisons [Top-down Camera] policy fails to locate the handle. [w/o Camera Pose Encoding] policy's actions are less precise, leading to errors like missing the shoe or misaligning the drawer.
1x
1x
1x
1x
Camera Views Visualizations
We visualize views from all 21 cameras during policy rollouts. Note that, in in the sweeping (small), robopanoptes is robust to the frame drops in the top view.1x
1x
1x
1x
1x
1x
1x
1x
Citation
@INPROCEEDINGS{XuX-RSS-25,
AUTHOR = {Xiaomeng Xu AND Dominik Bauer AND Shuran Song},
TITLE = {{RoboPanoptes: The All-Seeing Robot with Whole-body Dexterity}},
BOOKTITLE = {Proceedings of Robotics: Science and Systems},
YEAR = {2025},
ADDRESS = {LosAngeles, CA, USA},
MONTH = {June},
DOI = {10.15607/RSS.2025.XXI.042}
}